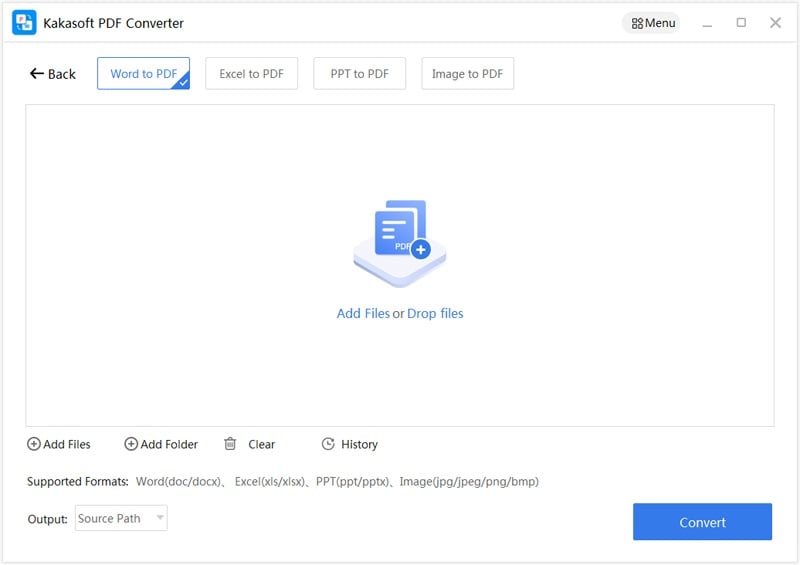
KakaSoft PDF Converter 2.0
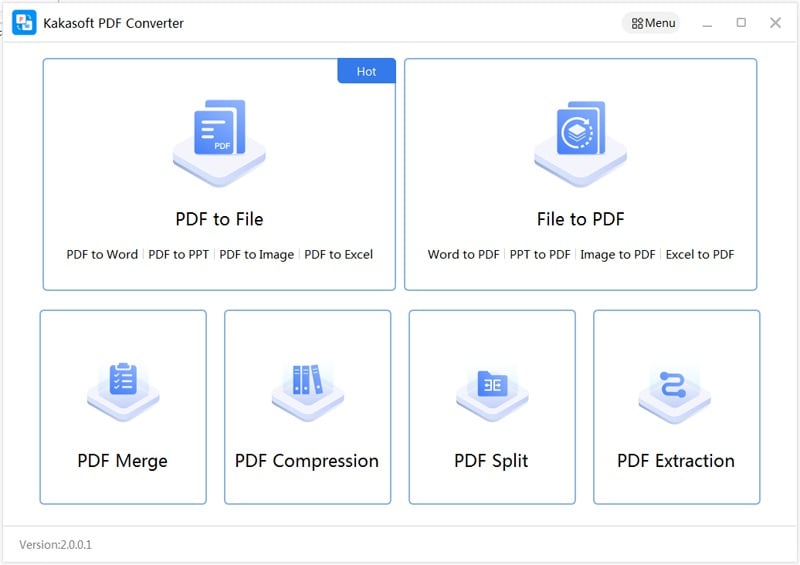
PDF Converter is the professional PDF converting software, which enables you to convert PDF to Word, Excel, PPT, HTML, JPG, etc., as well as compress, split, OCR, merge PDF, etc.
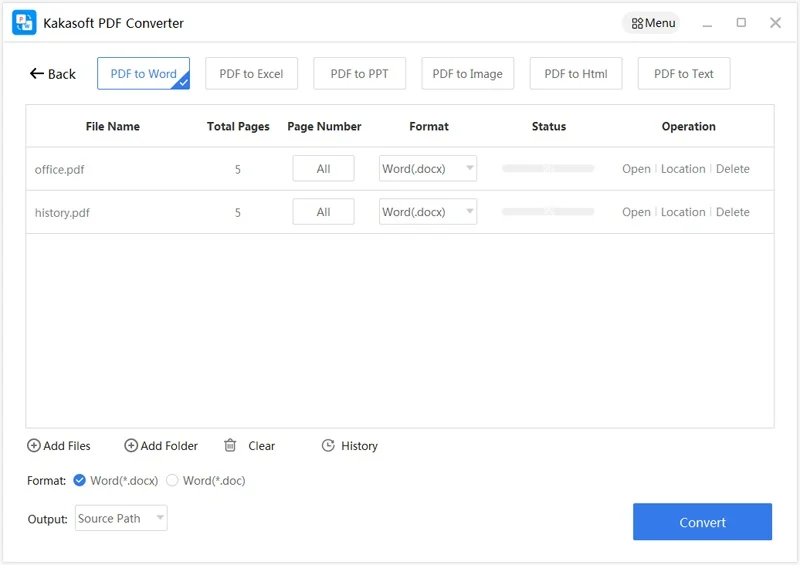
Convert PDF to Word/Text/Excel/PPT: Convert PDF files with texts, images, layout and format to Word/RTF file so that you can edit losslessly.
Advanced OCR Technology: Accurately recognize languages like English, French, Chinese, etc. in PDF file.
High Quality Output: The converted files keep exactly the same formatting and resolution as the original files. Enjoy a lossless conversion and a high-quality display of your files!
Batch Conversion: Enables you to import multiple PDF files and convert all of these PDF files at one time, or convert a section of a PDF file to remarkably improve your work efficiency.
Support 190 languages: Inserted powerful OCR technology supports English, German, French, Japanese, Korean, Turkish, Chinese, etc.
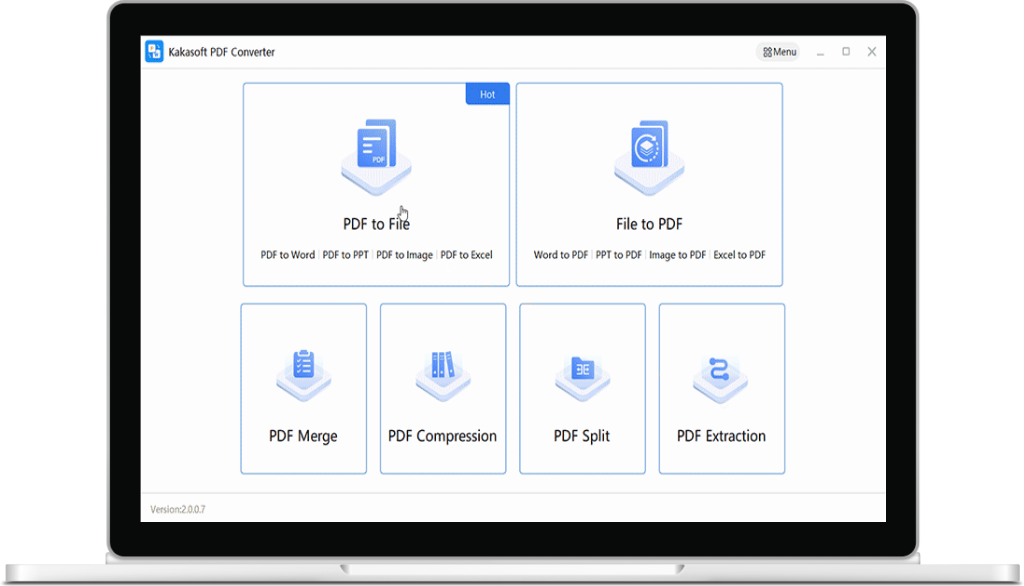
How to Convert PDF to other files with KakaSoft PDF Converter?
KakaSoft PDF Converter is an amazingly powerful tool that can improve your productivity.
Main Features of KakaSoft PDF Converter
PDF Converter is the professional PDF converting software, which enables you to convert PDF to Word, Excel, PPT, HTML, JPG, etc., as well as compress, split, OCR, merge PDF, etc.
Multiple Formats Supported
Quickly convert PDF to Word, Excel, PPT, JPG, PNG, TXT, HTML, and many more.
Batch processing
Add multiple files to the queue of the PDF Converter and convert them in a single click.
Advanced OCR technology
With OCR technology, the software recognizes over 190 languages like English, French, or Chinese, and more.
Convert selected page
Convert all, selected PDF pages to other formats or convert more than one PDF files at a time.
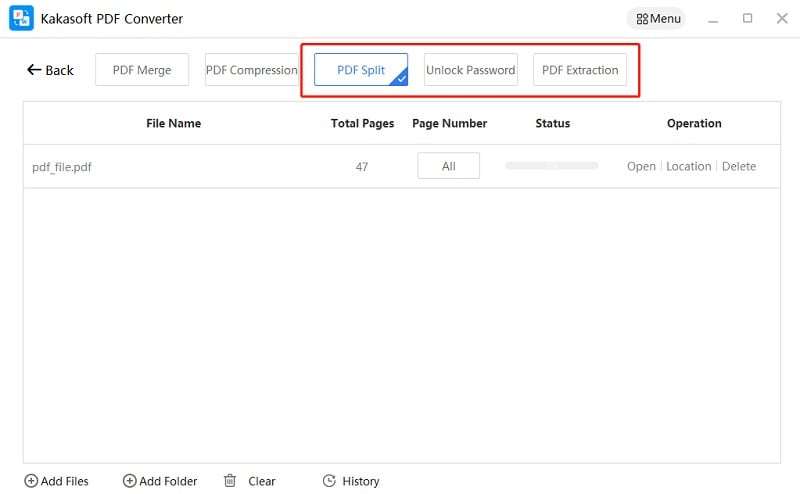
Merge & Split
Allows you to split pages of any PDF document no matter the length or file size, and merge several PDF files into a single file.
Convert large files
Convert files of any size both from and to PDF.
Batch Conversion
Enables you to import multiple PDF files and convert all of these PDF files at one time, or convert a section of a PDF file to remarkably improve your work efficiency.
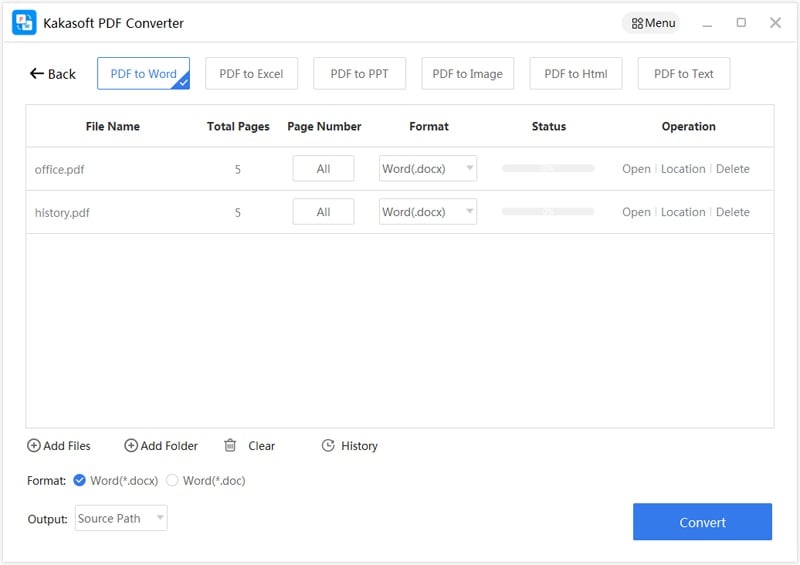
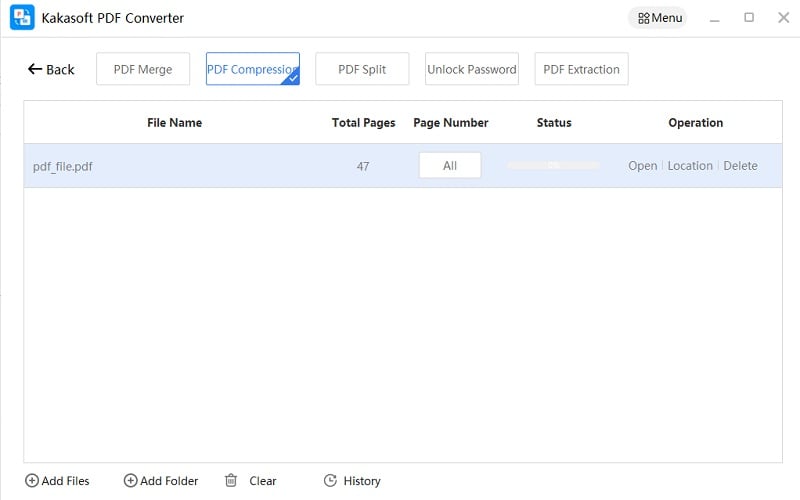
High Quality Output
The converted files keep exactly the same formatting and resolution as the original files. Enjoy a lossless conversion and a high-quality display of your files!
FAQs of KakaSoft PDF Converter
Here is an easy way to check whether an PDF document is a scanned PDF document:
a. Import the PDF file into your PDF reader.
b. Switch to text selection mode.
c. Try to highlight the text.
d. If the text can be highlighted, it is a normal PDF document.Otherwise, it is a scanned PDF document.
The program can recognize and convert normal PDF files especially for word-only ones well. If the output quality of the converted file is not so good, there are many factors:
a. The original PDF file is too complex and contain many elements such as pictures, graphs and so on.
b. The original PDF file is too blurry.
c. The color of the words is similar to the background in the original PDF file.
Please try different PDF files for more tests. Meanwhile, we are keeping optimizing the program and will release new versions periodically. Please expect.
OCR is an short for optical character recognition. It is a technique for extracting text from scanned PDF or image PDF files. It enables users to edit, copy, and search the text of scanned PDF/ images PDF documents.
If you just want to convert certain pages of a PDF file, click the Page Range field and type the page numbers need to be converted.
What People Are Saying

It not only spare me much of time but helped in security of my files while transferring. Happily Recommended!
– Nettie

I have to handle so much numerical data which is quite problematic. I edited all my pdf files into multiple mediums with this converter. Most of my work is in Excel and this converted all my data into an Excel file, in just seconds. I wonder where it has been my whole life.
– Hillary

I have Windows 8 and I never thought that there could be any application for such an old version but happy to use this converter. It converted the file into my desired size as well.
– Jackie

It is best for first-time users, I tried some applications online but wasn’t really able to go through the complexities. This one is definitely worth the money.
– Fannie